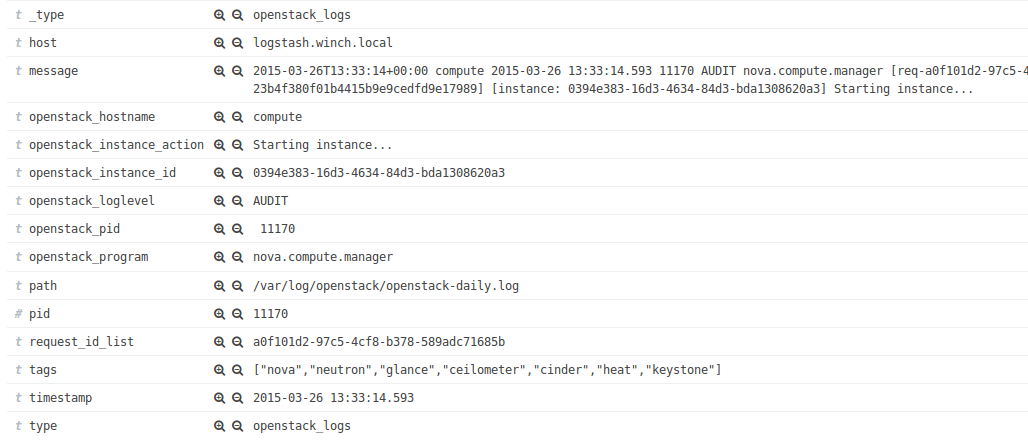
For å kunne hente ut informasjon fra data som kommer inn i Logstash kan man benytte seg av grok-filtre. Grok-filtre er bygget på toppen av regulære uttrykk og på bakgrunn av dette kan man hente ut den informasjonen man ønsker, eksempelvis fra loggdata. For å hente ut relevante data er man avhengig av å vite noe om dataene på forhånd. For eksempel sier følgende logglinje hvilken dato hendelsen skjer på, hvilket loglevel informasjonen er i, hvilken tjeneste som genererer meldingen og hvilken instans i OpenStack meldingen omhandler. At en instans starter kan være nyttig informasjon dersom den ikke skulle komme opp som forventet.
2015-03-20T08:38:51+00:00 compute 2015-03-20 08:38:51.292 11139 AUDIT nova.compute.manager [req-414b1736-9bf6-4457-a848-1295ebb12d7c b251c86204eb44b6822a998da0d28ad4 1a49bb7c49914d96b95ade9b1345eac2] [instance: 4e86c611-0914-4da2-9ed4-4c2ca5529ffb] Rebooting instance
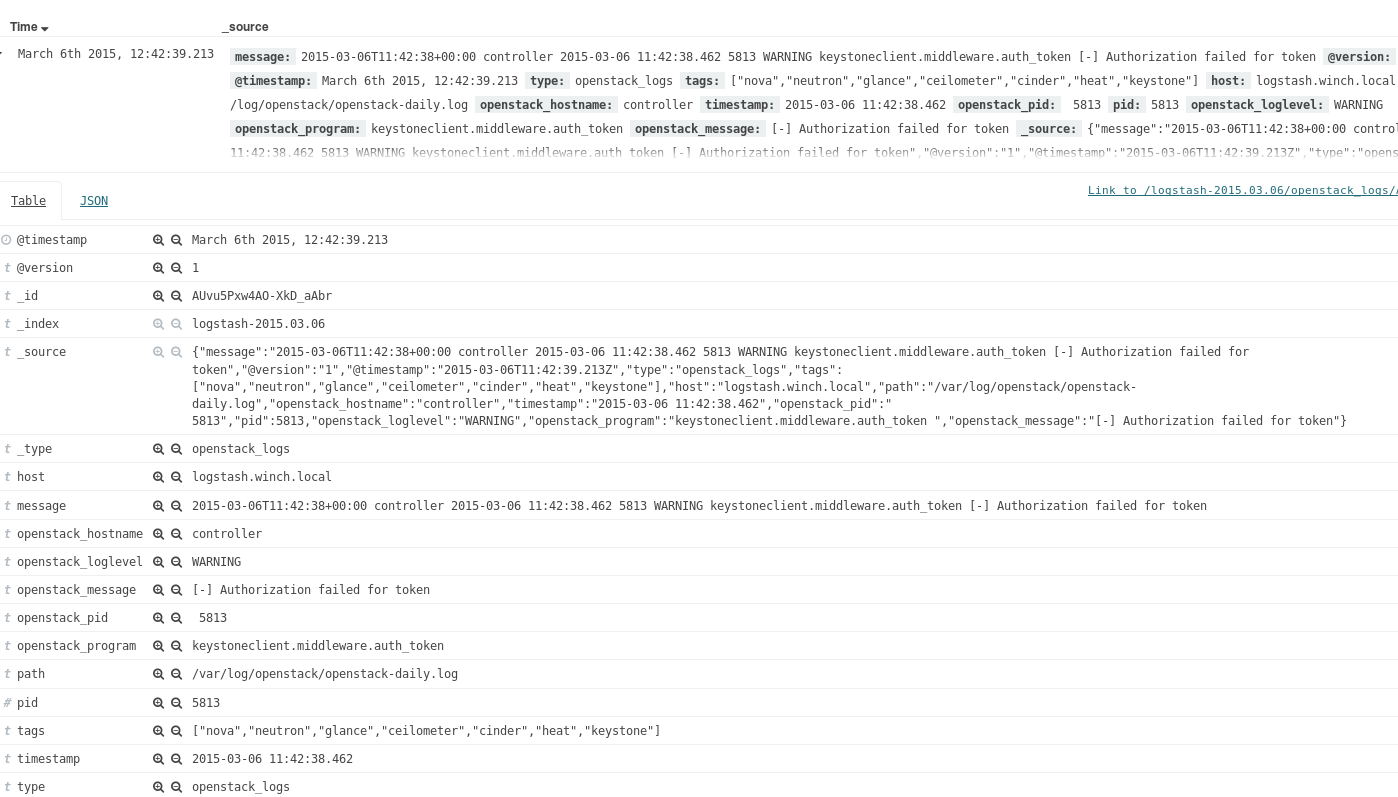
Ved hjelp av grok debugger har jeg laget et filter som henter ut informasjonen og gjør den svært oversiktlig og enkel å organisere. Etter at informasjonen er kommet gjennom filteret ser den slik ut:
{
"openstack_hostname": [
"compute"
],
"timestamp": [
"2015-03-20 08:38:51.292"
],
"openstack_pid": [
" 11139"
],
"openstack_loglevel": [
"AUDIT"
],
"openstack_program": [
"nova.compute.manager "
],
"request_id_list": [
"414b1736-9bf6-4457-a848-1295ebb12d7c",
"1a49bb7c49914d96b95ade9b1345eac2"
],
"openstack_instance_id": [
"4e86c611-0914-4da2-9ed4-4c2ca5529ffb"
],
"openstack_instance_action": [
"Rebooting instance"
]
}
Dette sendes så videre fra Logstash til Elasticsearch der man kan søke opp spesifikke data og visualisere dette på mange ulike måter. Visualisering vil bli et eget tema på bloggen senere.