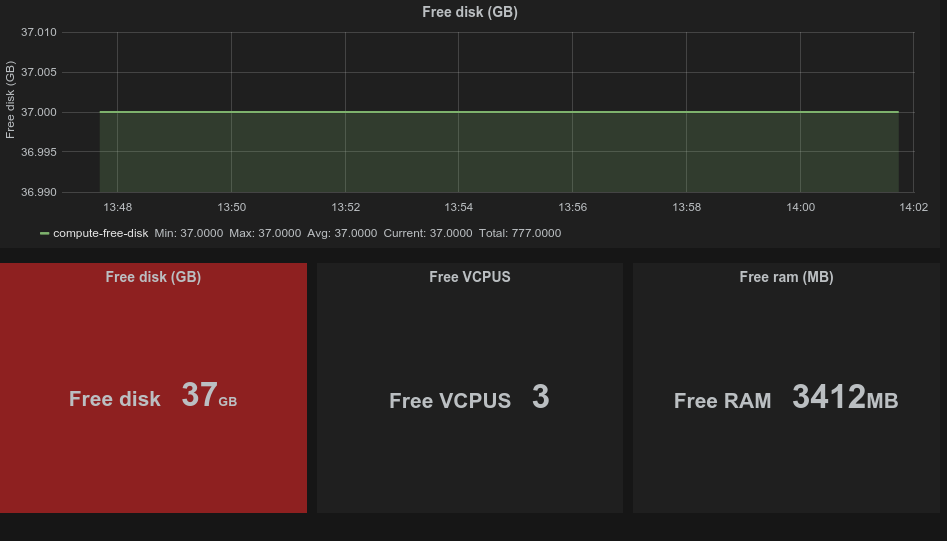
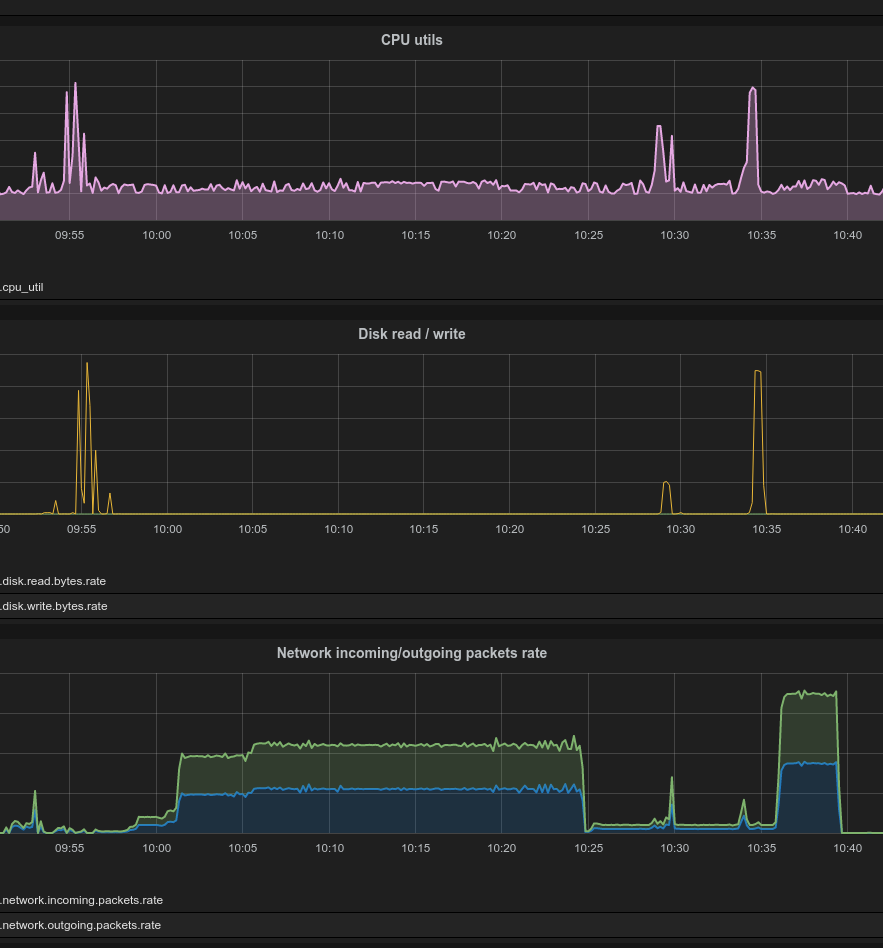
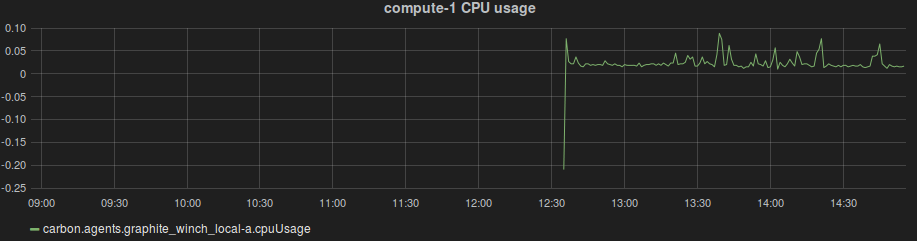
Siden vi allerede ekstraherer alle loggmeldinger som genereres i OpenStack kan vi også hente ut og visualisere API-responskoder og API-responstider. Dette grafes på følgende måte: 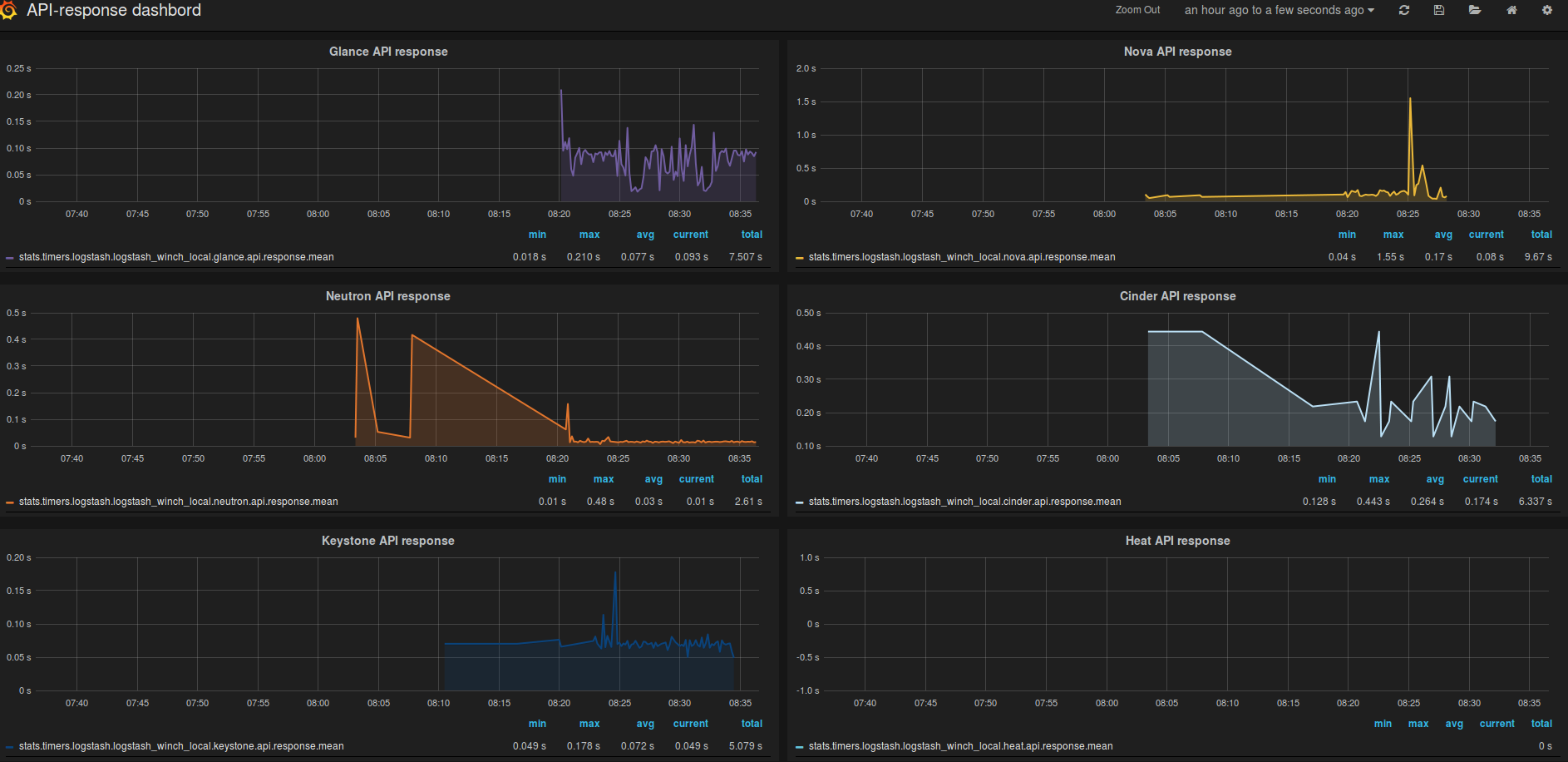
Med en API responstid følger også en responskode. For å se hvor mange ganger responskodene forekommer i forhold til hverandre kan dette visualiseres på denne måten:
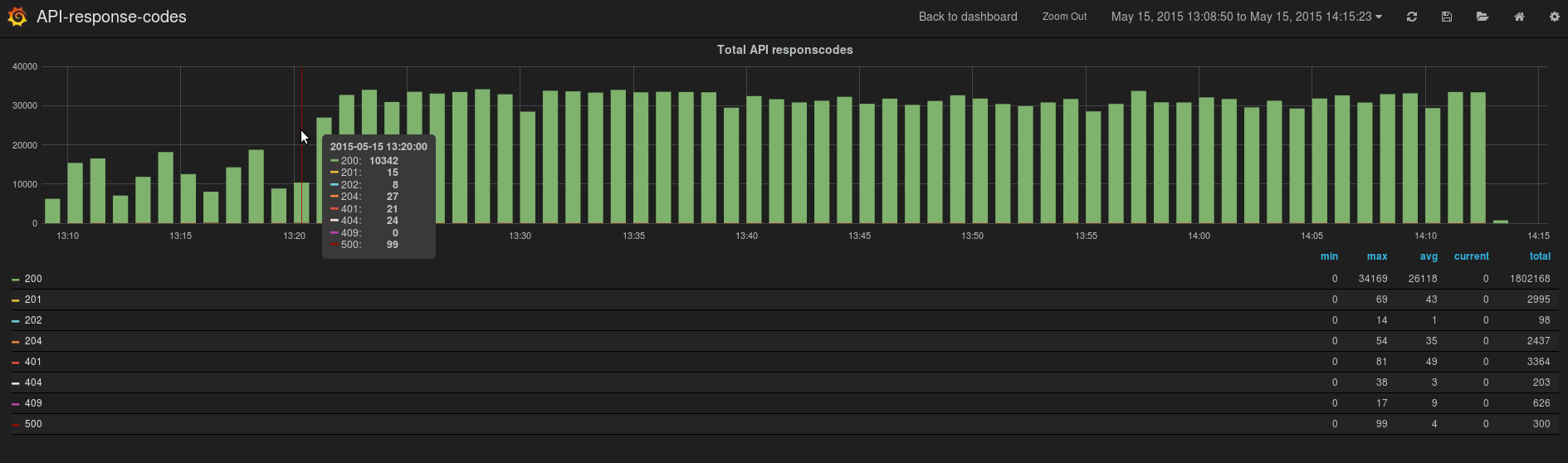
Etter helgen 17. mai vil jeg hovedsaklig fokusere på å fullføre et utkast til prosjektrapporten som skal inn den 26. mai. Endelig innleveringsfrist er satt til 9 juni og prosjektrapporten vil selvfølgelig bli publisert på bloggen.