This blog post is a summary of the first 14 days of work on my bachelor degree. It is written in English to satisfy some of our Brazilian readers at the University in São Paulo.
Openstack consists of many different services and components, and all of these services are logging information to their own log files respectively. However, it would be an impossible job for a system administrator to monitor all of these log files by simply tailing them through the terminal. This is where Logstash is useful. Logstash is an open-source tool for managing events and logs. It is primarily used for collecting logs, parsing them and save them for later use. The tool also comes with an interface for searching in the logs you’ve collected.
Based on the winch project on GitHub I have created a Logstash node where all logs coming from OpenStack have been centralized. On this node all logs are parsed, information extracted and saved in Elasticsearch. Seconds after, the extracted information is visible on the Kibana dashboard (a front-end to Elasticsearch) ready for searching, filtering and visualization. Extracting the information from the log files is a bit more complex than it sounds. However, Logstash is very easy to get started with and once the basics are covered you’re ready to write complex filters yourself. Having the grok debugger in hand and a quick tutorial in the other also helps 🙂
In my configuration I’m pretty much finished with the filters that covers all the lines of log that the nova services in OpenStack are generating. Launching, rebooting, deleting instances and error messages related to instances is now hit by a filter in Logstash and saved for later searches. Additionally I’ve made a filter that caches everything that is not matched by any previous filter in the configuration. This is in case some special event should occur or if the system goes haywire (not that I expect that to happen). The ‘all-matching’ filter is tagged with «unmatched_event» , and from here we can go back and change the original filter to take «these» special events into account. By doing this we will at all times have an overview if something should go wrong. Also we won’t miss any data that somewhat could be important for us to know. The Logstash configuration can be found here.
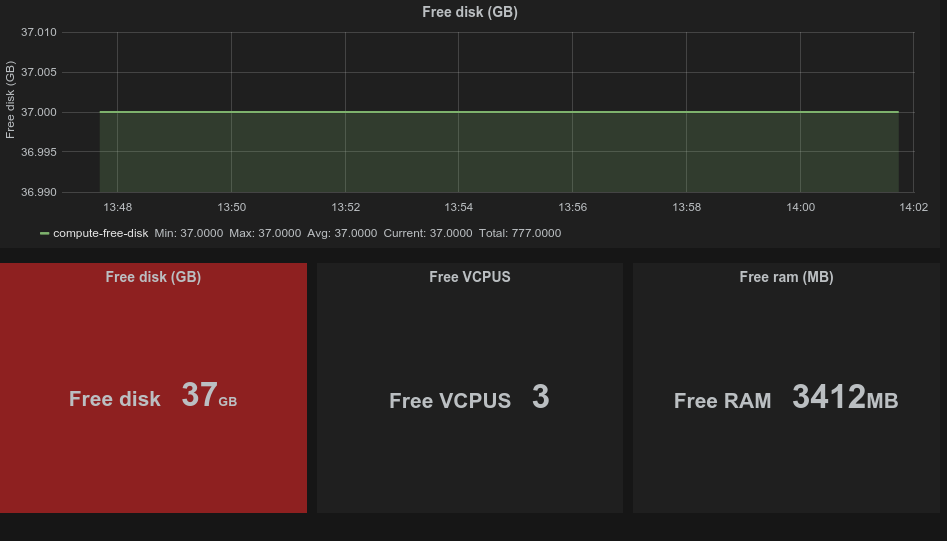
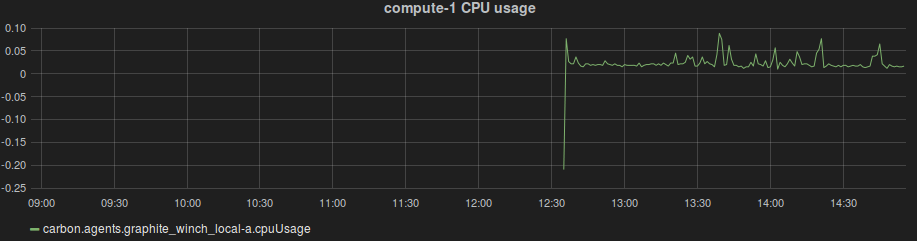
Further on I’ve also created some metrics which can been seen in the configuration file. Winch monitoring also consist of a Graphite node where these metrics are sent and visualized. I believe that some data are best when they are graphed in some way or the other providing an overview on a day-to-day basis (or even minute-to-minute basis) on how the system is performing. Graphs also helps seeing systems in context which is very useful.
During the next couple of weeks I will continue to make filters, extract data from logs until all OpenStack services are covered, visualize data and put data in context by making graphs and much more. Stay tuned!