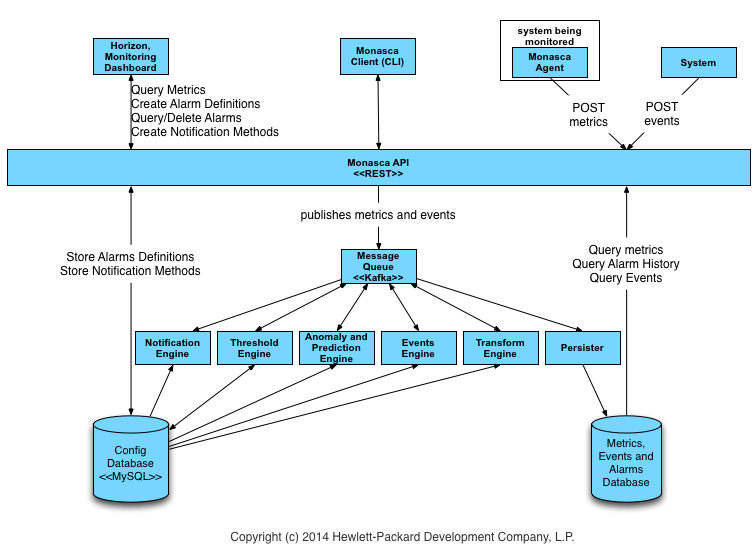
Som tidligere publisert på bloggen har jeg fått tildelt en 32GB fysisk blade server der winch har blitt installert. Hensikten med dette er å kjøre et virtuelt OpenStack-testmiljø der jeg kan teste ulike monitoreringssystem. For øyeblikket er jeg i gang med å teste Logstash, Elasticsearch og Kibana og har satt opp dette i winch under en egen monitoreringsbranch. I denne branchen har jeg laget en logstash node som er konfigurert til å ta imot alle loggdata som kommer fra OpenStack.
Her vil jeg ha muligheten til å se hvilke data som kommer inn slik at jeg kan hente ut den informasjonen som er relevant. Samtidig ønsker jeg å kunne filtrere vekk all unyttig informasjon slik at dette ikke overskygger viktige data. Jeg har laget en vagrantboks som installerer Logstash automatisk ved hjelp av puppet. Dersom noe feil skulle skje eller testoppsettet ikke skulle fungere som det skal, kan jeg enkelt slette og starte maskinen på nytt for å komme tilbake til der jeg var før feilen skjedde. Ved hjelp av dette sparer jeg mye tid og kan fokusere mer på testingen av de ulike verktøyene. Vagrantboksen er definert slik.