Etter tips fra prosjektleder i UH-sky prosjektet er et av monitoreringsverktøyene jeg har valgt å se på logstash. Et kraftig verktøy som brukes til å håndtere hendelser og logger.

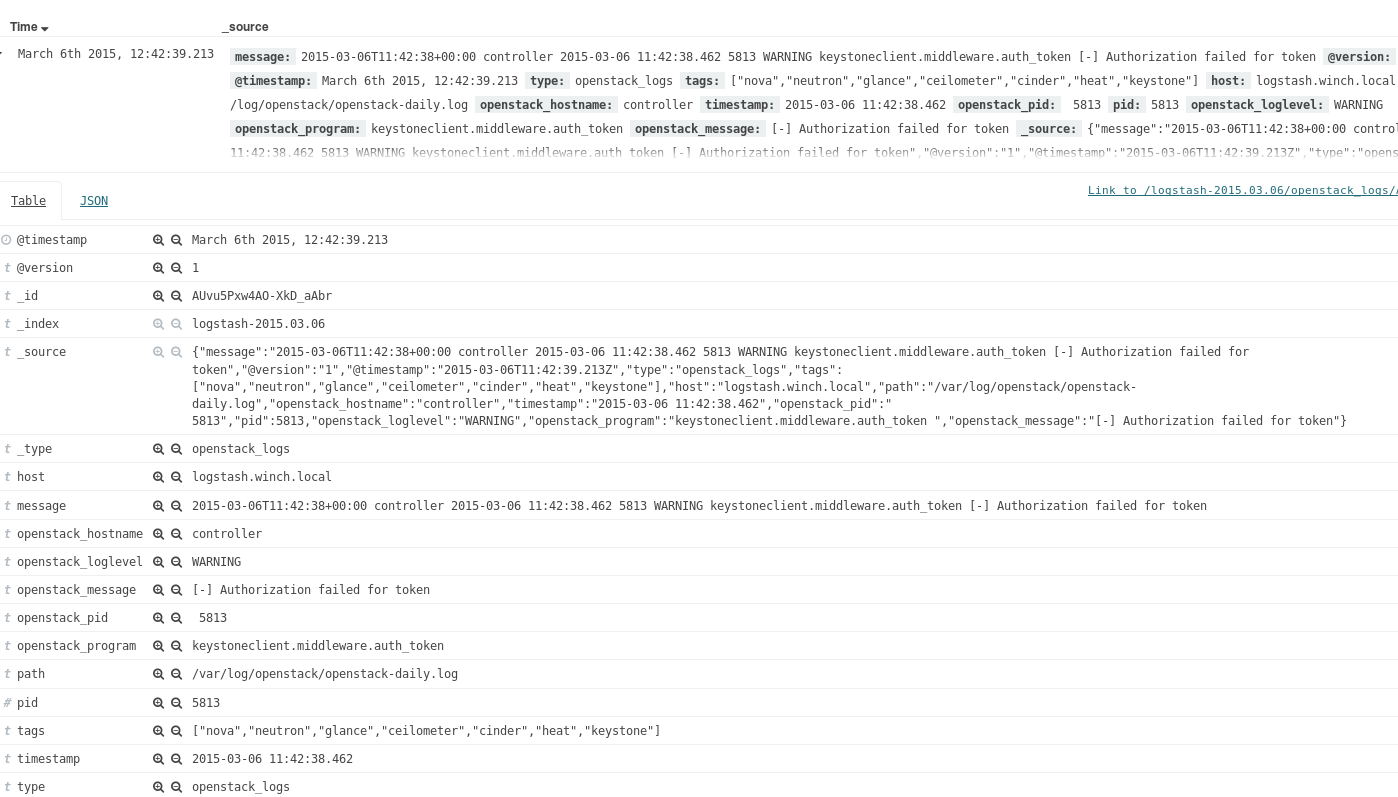
Logstash samler inn logger fra ulike kilder, parser loggene og lagrer de til senere bruk. Når man installerer logstash kommer det også med et webinterface der man kan søke etter hendelsene i loggfilene og visualisere dette slik man ønsker. Dette for å kunne kartlegge feil, se endringer i systemer over tid, sette sammen data som har påvirkning på herandre osv. Logstash er et åpent kildekodeverktøy og er lisensiert under Apache 2.0.
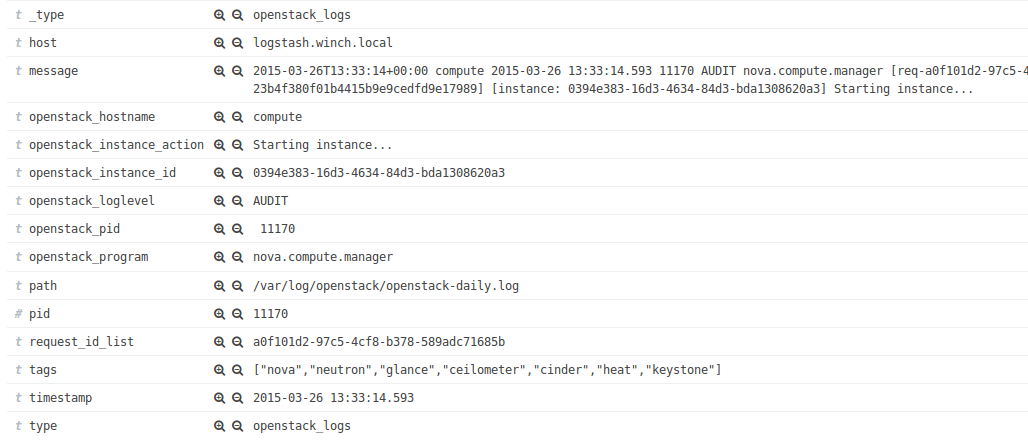
OpenStack er et komplekst rammeverk som består av mange tjenester. Hver tjeneste har sitt eget bruksområde og sitt eget API. Det er mye informasjon som til daglig vil være spredt rundt om i systemet. Dette gjør det viktig å samle all loggdata på et samlet sted slik at det blir enklere å hente ut den informasjonen vi trenger for å sørge for at rammeverket til enhver tid fungerer som det skal. Logstash er veldig egnet til dette formålet. I logstash.conf kan vi tagge innkommende logger og videre kan det så kjøres filter basert på disse taggene for å hente ut den spesifikke informasjonen vi vil ha tak i. For eksempel tjenestenavn, diskbruk, antall påloggingsforsøk, brukere, IP adresser, nettleser osv. Alt av informasjon som finnes i en loggfil kan ekstraheres, lagres og videresendes til en eller annen form for visualisering.
Jeg har til nå arbeidet med en kodebase som jeg forket på github som installerer disse tre verktøyene som nevnt i overskriften. Videre har jeg tenkt å integrere denne mot winch slik at den passer øvrig prosjektstruktur. Under følger et bilde av hvordan visualiseringen av loggdataene ser ut.