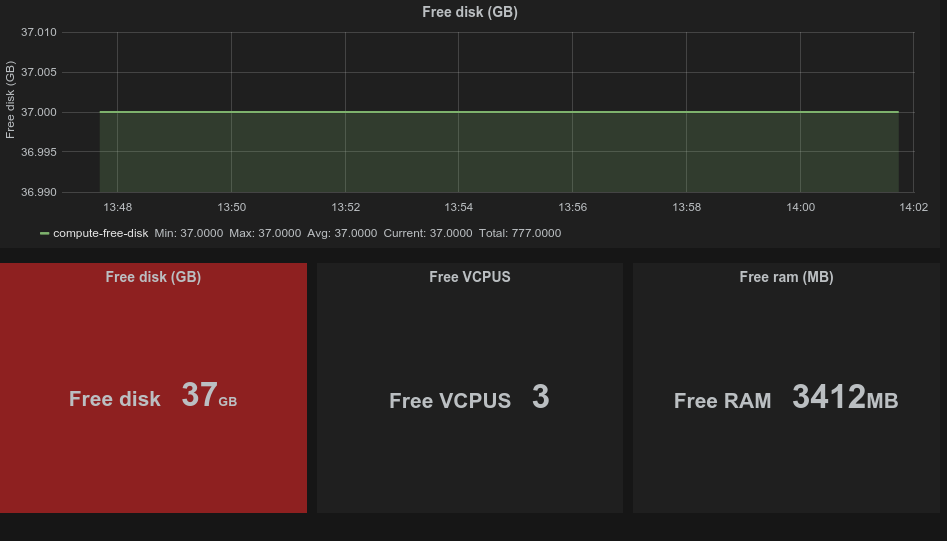
Har gjennom hele uken eksperimentert med å lage metrics utav loggene som kan sendes fra logstash til Graphite for grafing. Det som kan grafes så langt er tilgjengelige ressurser på alle compute nodene i OpenStack. Tanken er at disse grafene skal kunne eksponeres ut mot brukerne slik at en kan se hvor mye ressurser det er tilgjengelig til enhver tid på hver av nodene.
I tillegg har jeg laget noen python scripts som skal brukes til å hente ut spesifikke instansdata som også skal kunne grafes. Videre skal jeg også se på muligheten til å hente ut data fra Ceilometer.