Noe mer konfigurasjon måtte til for at den nye grafnoden skulle fungere som den skulle. Provisjonering av noden måtte kjøres to ganger, i tillegg til at en rekke småting måtte konfigureres manuelt. Med alle disse hindringene til side var det tid for å generere noen grafer.
Ved hjelp av et script som heter ceilometer publisher har jeg hatt mulighet til å pushe enkelte data direkte fra ceilometer og inn til Graphite. Data som cpu- og minnebruk har vært de to mest aktuelle, og ved å opprette instanser i OpenStack har jeg kunne sett at grafene utvikler seg over tid. Dette gir et interessant overblikk over tilgjengelige ressurser på systemet og hjelper oss å se data i sammenheng. Samtidig som det også tilbyr systemadministratorer proaktiv overvåkning ved å kunne forutse og hindre problemer før de oppstår.
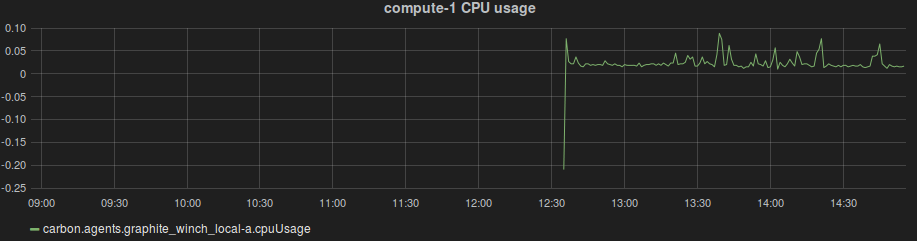
Når man skal sette opp grafer i Graphite/Grafana baserer man seg på såkalte metrics. Hvis man for eksempel ønsker å se på CPU bruk på en maskin het metric’en i vårt tilfelle: carbon.agents.graphite_winch_local-a.cpuUsage. Denne visualiseres slik: