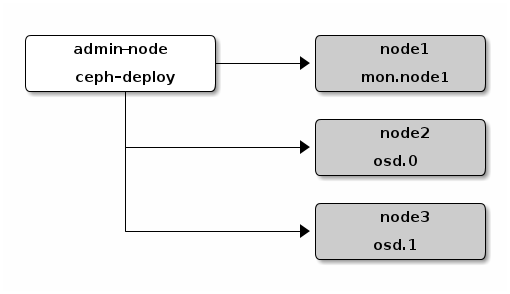
Fra forrige gang fant jeg ut at et Ceph kluster ikke kan provisjoneres node for node. Dette ble også bekreftet av en av utviklerne fra Stackforge. På bakgrunn av dette laget jeg et script som tar opp alle nodene samtidig. I tillegg ble det lagt inn en 10 sekunders forsinkelse mellom hver av maskinene slik at vi får korrekt IP adresse på dem. Scriptet er et veldig enkelt script som kan sees i sin helhet på Github.
Nå vil ikke timeout feilen fra forrige innlegg skje. Når den kommer til punktet der nøklene skal sendes over til de andre maskinene i ceph klusteret vil de andre nodene også ha kommet til dette steget. På denne måten klarer nøklene å spres over til de andre maskinene og provisjoneringen med puppet går gjennom uten feil.
Videre arbeid blir nå å integrere ceph med resten av OpenStack slik at instansene vi oppretter bruker ceph som lagringsområde. I tillegg skal jeg skrive en del dokumentasjon om winch og hvordan man tar det bedre i bruk. Foreløpig dokumentasjon kan sees på http://winch.readthedocs.org/en/latest/