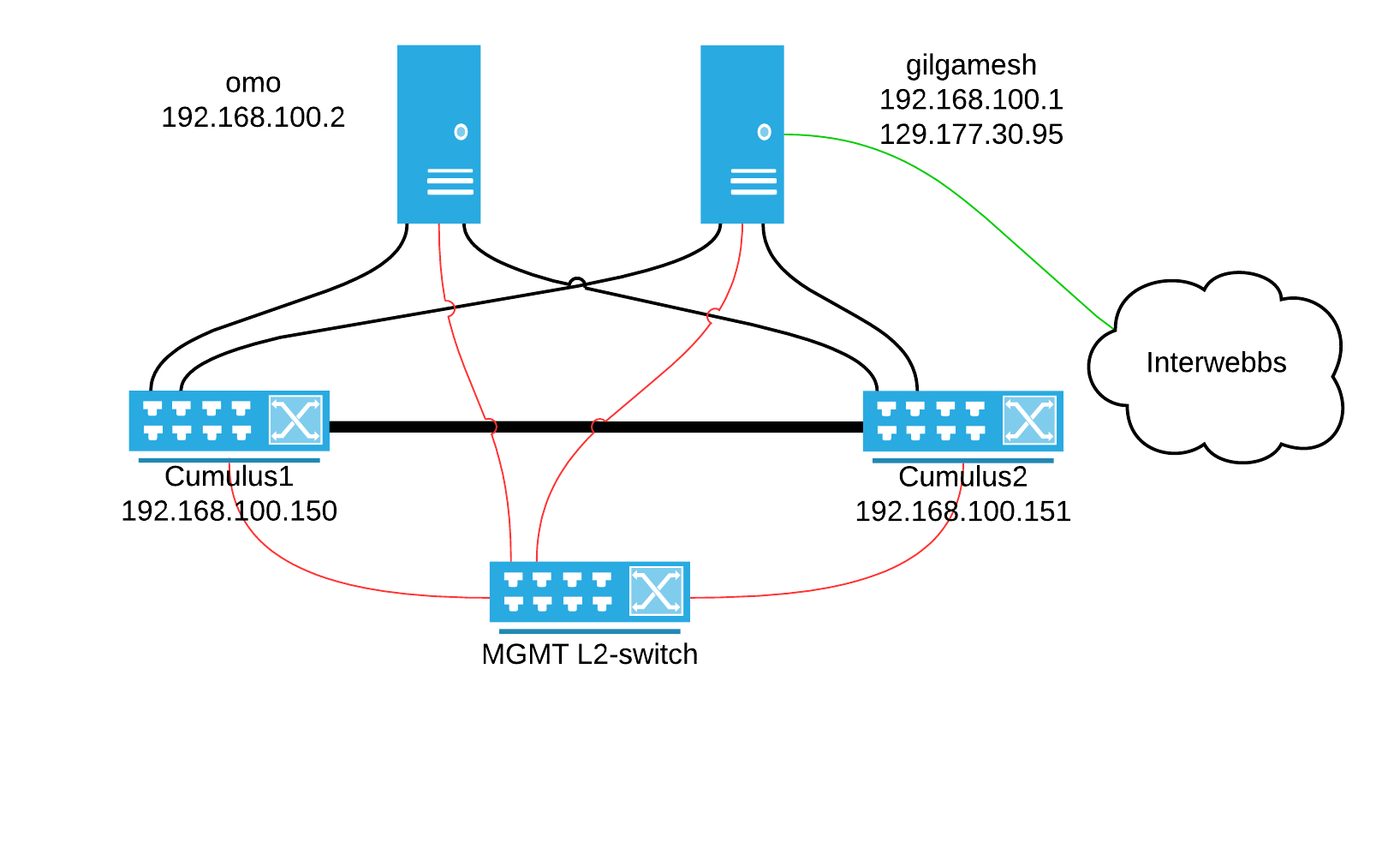
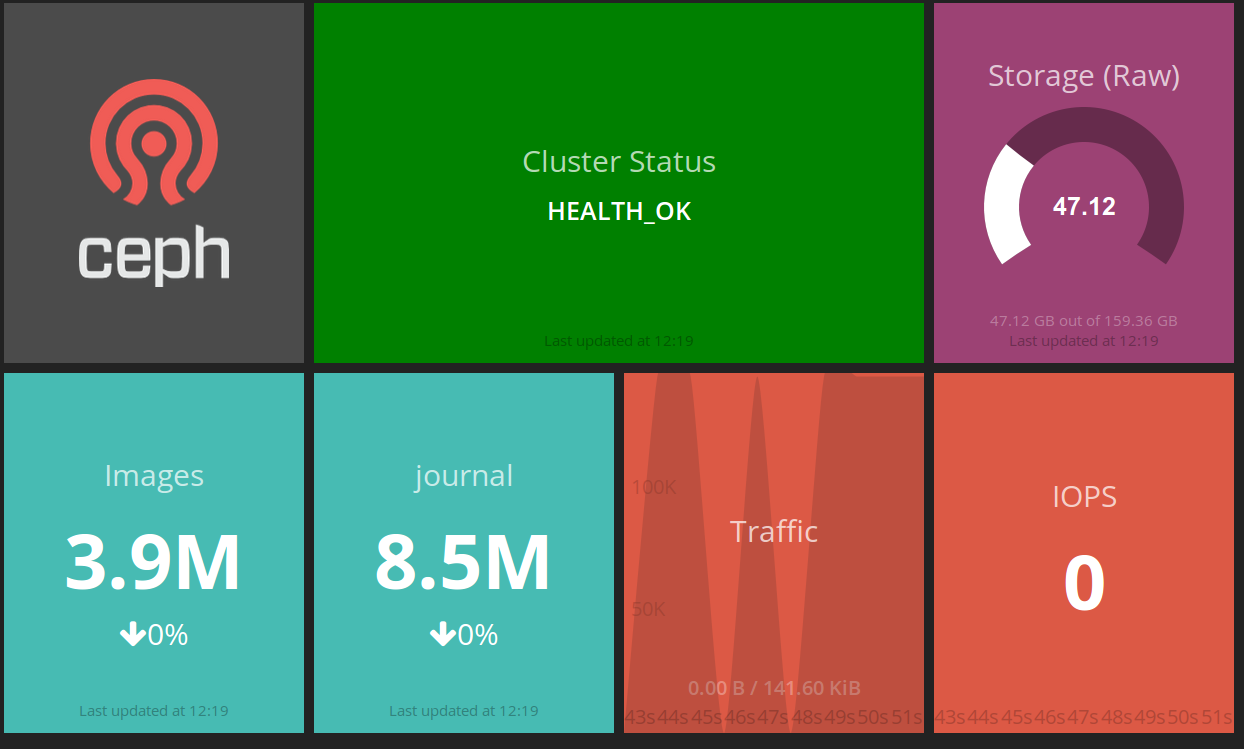
Den siste uken har gått med til å sette opp dashing-ceph, dashing-openstack, rydding av Logstash config og oppdatering av bacheloroppgaven. Dashing er kort fortalt et dashbord rammeverk for å visualisere informasjon i «fine bokser», se bilde nedenfor. Det er mye ting i luften akkurat nå og det kommer til å bli en hektisk tid fremover mot innleveringen andre uken i juni.
Bachelorprosjektet skal framføres enten den 10, 11 eller 15 juni og alle som er interessert må komme å høre på! Planen er å ha en enkel men oversiktlig presentasjon med live demo som viser hva jeg har jobbet med dette semesteret. I uken som kommer vil de siste tekniske bitene bli implementert før skriveperioden starter for fullt.